고정 헤더 영역
상세 컨텐츠
본문
반응형
2020.08.24
[패스트캠퍼스 수강 후기] 데이터분석 강의 100% 환급 챌린지 15회차 미션
어제는 데이터 파일을 가지고 비어있는 값을 지우거나, 중복된 값을 지우는 방법을 배웠는데, 평균, 중위값으로 대치하여 결측값을 제거하여 데이터를 분석할 수 있어 실제로 판매업적, 고객 데이터를 정리하는 데 실용적 일 것 같다는 생각이 들었다. 아직까지는 간단하고 열과 행이 많지 않은 예제를 다루기 때문에 따라가기 쉬웠다. 오늘은 서로 다른 dataframe 파일을 합치는 코딩 방법을 배웠다.
dataframe 파일을 합치는 것으로, concat과 merge있다.
concat은 row나 column 기준으로 단순하게 이어 붙이는 방법이고 merge는 특정 기준index으로 병합하는 방법으로 이해했다.
📍 dataframe concat
dataframe을 단순하게 이어 붙이는 방법으로는 열을 기준으로, 행을 기준으로 합치는 방법이 있다.
👉 row기준으로 합치기
row에 합칠 때는 pd.concat에 합칠 데이터프레임을 list로 합쳐주고, 옵션으로 sort=False을 써서 순서가 유지되도록 할 수있다.
df_concat = pd.concat([df 이름,df 이름],sort=False)
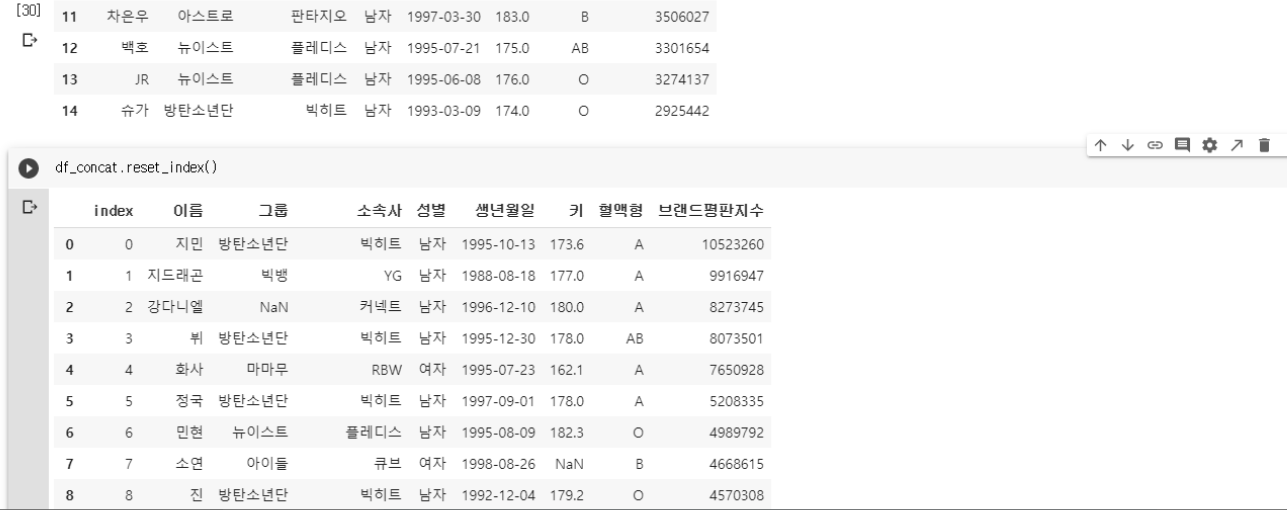
이때, 두 데이터의 인덱스가 이어지지 않는데, 인덱스를 통일시키기위해서 df_concrat.reset_index()를 하면 위의 실습파일 처럼 인덱스 행이 나오면서 이어진다. 괄호를 하지않으면, 엑셀 형태로 나오지 않는다는 것을 실습하면서 또 하나 알아간다 ㅎㅎ
👉column기준으로 합치기
column을 기준으로 합치고자 할 때는 axis=1 옵션을 추가해야한다. 이렇게 pd.concat([df, df2], axis=1) -
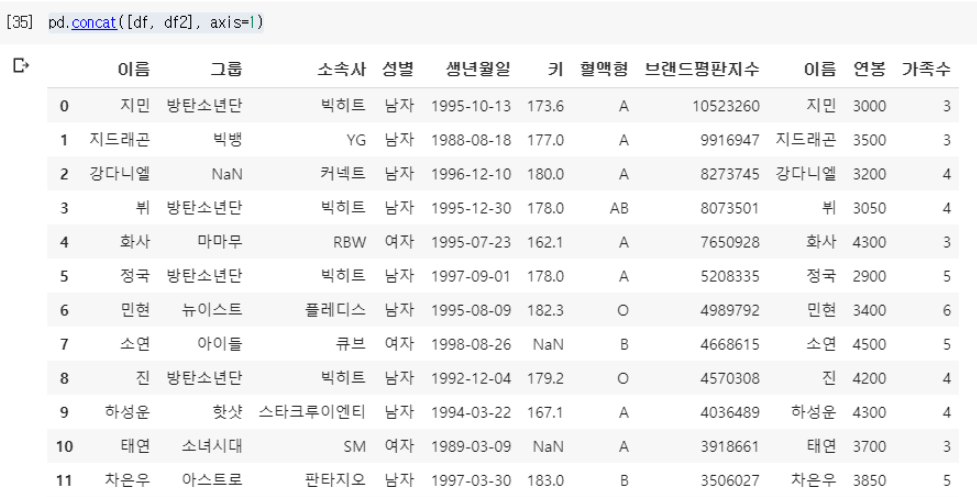
해보니, 위 실습파일과 달리 옆으로, 가로로 엑셀파일이 넓어졌다!
merge
merge는 두 dataframe 중 하나를 기준 column으로 해서 데이터를 병합하는 것으로 이해했다. 'left', 'right', 'inner', 'outer' 라는 4가지의 병합 방식중 한가지를 선택할 수 있다. 코딩식으로는,
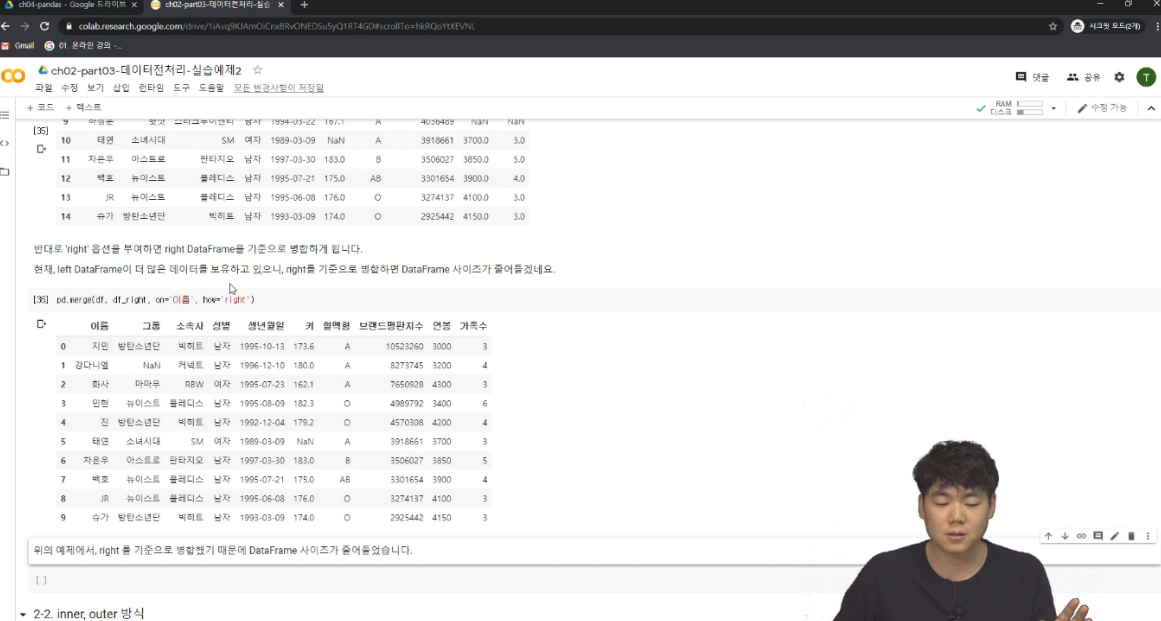
pd.merge(left Df파일, right Df파일, on='병합의 기준이 되는 column', how='left'/right)
- left와 right를 했을때 차이점은 기준을 left로 하고 없는 값들은 NaN로 바뀌지만, 기준을 right으로 하면 없는 값들은 자동으로 drop되는 것이었다.
- inner 둘다 있는 경우 즉, And교집합의 개념
- outer은 모두 합하는 Or합집합의 개념이었다.
생소한 개념이라 강의 3번 들어서 개념은 정리했지만 다른 예제로 더 실습을 해봐야겠다. left_on과 right_on라는 응용법도 배웠는데 이건 elft,right,inner,outer부터 확실히 정리하고 실습해봐야겠다.
💡오늘 배운 내용 복습
- concat: row나 column 기준으로 단순하게 이어 붙히기 → 행과 열을 기준
- merge: 특정 고유한 키(unique id) 값을 기준으로 병합하기
강의를 들으서 따라갈때는 다 이해한 것 같아도 혼자서 실습을 해보면 자꾸 오류가 뜰때가 있다. 이래서 실습이 중요한 가보다.. 02. 파트1 19강 &20강 수강완료!✊
직장인을 위한 파이썬 데이터분석 올인원 패키지 Online. | 패스트캠퍼스
왕초보도 진짜 데이터 분석을 하는 마법의 커리큘럼으로 파이썬 기초부터 다양한 예제를 활용한 분석까지 모두 배울 수 있는 온라인 과정입니다.
www.fastcampus.co.kr
반응형
'같이 공부해요 > 패스트캠퍼스ㅣ직장인을 위한 파이썬 데이터분석 올인원 패키지 Online' 카테고리의 다른 글
| [패스트캠퍼스 수강 후기] 데이터분석 강의 100% 환급 챌린지 17회차 미션 (0) | 2020.08.26 |
|---|---|
| [패스트캠퍼스 수강 후기] 데이터분석 강의 100% 환급 챌린지 16회차 미션 (0) | 2020.08.25 |
| [패스트캠퍼스 수강 후기] 데이터분석 강의 100% 환급 챌린지 14회차 미션 (0) | 2020.08.23 |
| [패스트캠퍼스 수강 후기] 데이터분석 강의 100% 환급 챌린지 13회차 미션 (0) | 2020.08.22 |
| [패스트캠퍼스 수강 후기] 데이터분석 강의 100% 환급 챌린지 12회차 미션 (0) | 2020.08.21 |





댓글 영역