고정 헤더 영역
상세 컨텐츠
본문
반응형
2020.09.16
[패스트캠퍼스 수강 후기] 데이터분석 강의 100% 환급 챌린지 38회차 미션
37회차에서 LogisticRegression, SGD Classifier, 하이퍼 파라미터 (hyper-parameter) 튜닝를 배우고 오늘은 이어서 최근접 이웃 알고리즘과 의사 결정나무 진도를 나갔다.
📎 최근접 이웃 알고리즘 KNeighborsClassifier
최근접 이웃 알고리즘은 k의 갯수를 지정해서 최근접에 있는 몇 개의 데이터까지 볼건가..? 하는 알고리즘이다.
knc = KNeighborsClassifier()
knc.fit(x_train, y_train)
knc_pred = knc.predict(x_valid)
(knc_pred == y_valid).mean()
아래 예시를 보면,
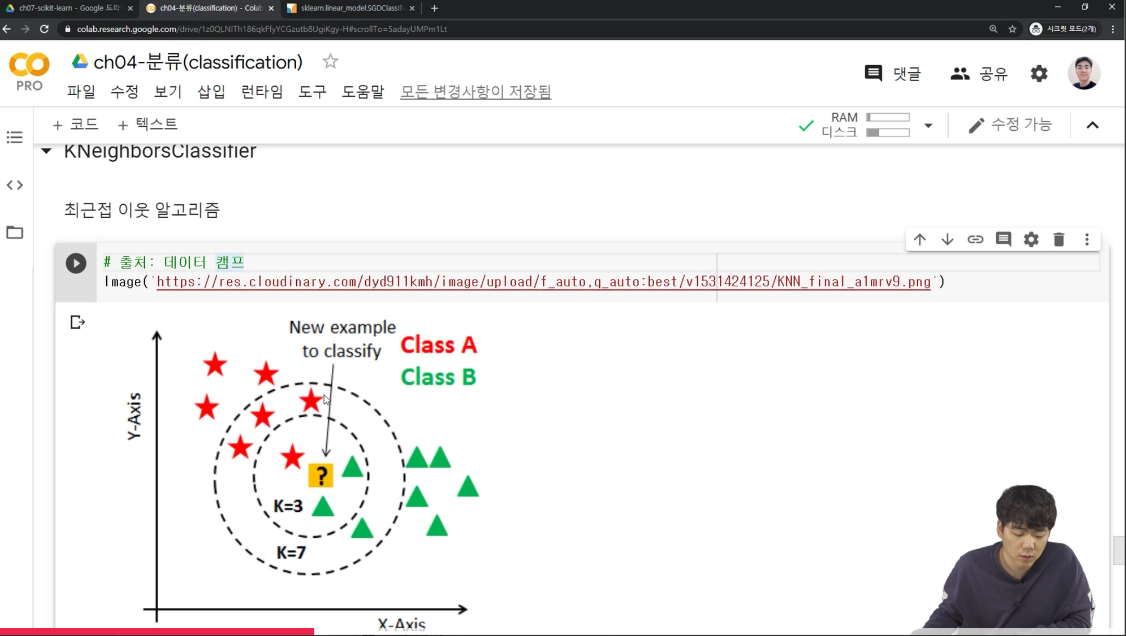
k가 3인 경우, 클래스 B가 많기때문에 클래스 B데이터로 으로 분류하고, k가 7인 경우 최근접에 클래스 A 데이터가 많기 때문에 클래스 A로 분류할 수 있다.
k를 설정할 때는 일반적으로 홀수개를 넣는다. 짝수의 경우 동점확률이 생기기 때문에! KNeighborsClassifier의 경우도, 앞에서 처럼 neigherbors에 따라 모델성능이 달라질 수있기 때문에, n을 여러개로 시도해보고 설정해야한다!
📎 의사 결정 나무 (Decision Tree)
의사 결정 나무는 스무고개처럼 질문을 해서? 클래스로 나누는 것으로 이해했다. 예를 들면, 키가 170이 넘어? 예/아니오로 분류하고 그다음, 몸무게가 80이상이하? 분류→ 즉, 클래스를 가지치기하면서 분리하는 것을 말한다.
from sklearn.tree import DecisionTreeClassifier
dtc = DecisionTreeClassifier(random_state=0)
dtc.fit(x_train, y_train)
dtc_pred = dtc.predict(x_valid)
(dtc_pred == y_valid).mean()
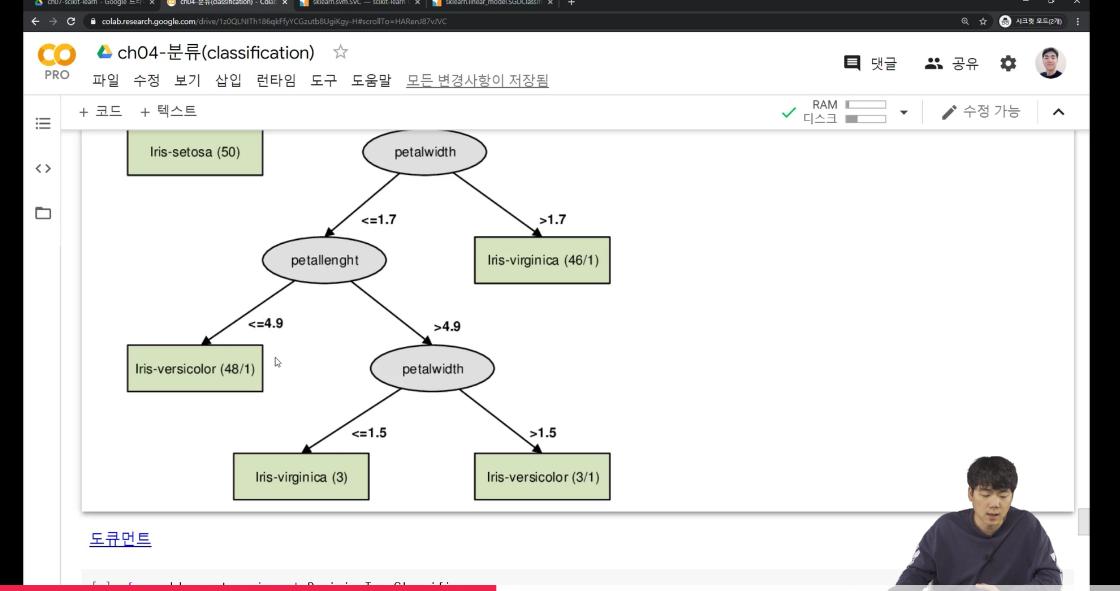
강사님의 예제를 보면, petalwidth가 1.7이하인 경우 petallenght로 분류, 초과인 경우 iris-virginica 이런식으로!
💡오늘 배운 내용 복습
-
최근접 이웃 알고리즘 KNeighborsClassifier
-
의사 결정 나무 (Decision Tree)
04. Part 1 22강&23강까지 수강완료!✊
직장인을 위한 파이썬 데이터분석 올인원 패키지 Online. | 패스트캠퍼스
왕초보도 진짜 데이터 분석을 하는 마법의 커리큘럼으로 파이썬 기초부터 다양한 예제를 활용한 분석까지 모두 배울 수 있는 온라인 과정입니다.
www.fastcampus.co.kr
반응형
'같이 공부해요 > 패스트캠퍼스ㅣ직장인을 위한 파이썬 데이터분석 올인원 패키지 Online' 카테고리의 다른 글
| [패스트캠퍼스 수강 후기] 데이터분석 강의 100% 환급 챌린지 40회차 미션 (0) | 2020.09.18 |
|---|---|
| [패스트캠퍼스 수강 후기] 데이터분석 강의 100% 환급 챌린지 39회차 미션 (0) | 2020.09.17 |
| [패스트캠퍼스 수강 후기] 데이터분석 강의 100% 환급 챌린지 37회차 미션 (0) | 2020.09.15 |
| [패스트캠퍼스 수강 후기] 데이터분석 강의 100% 환급 챌린지 36회차 미션 (0) | 2020.09.14 |
| [패스트캠퍼스 수강 후기] 데이터분석 강의 100% 환급 챌린지 35회차 미션 (0) | 2020.09.13 |





댓글 영역