고정 헤더 영역
상세 컨텐츠
본문
반응형
2020.09.23
[패스트캠퍼스 수강 후기] 데이터분석 강의 100% 환급 챌린지 45회차 미션
📈Polynomial Features
선형함수로 계속 실습을 했는데, feature의 개수가 많아질때 즉 인풋이 많아질때 계수?값을 바꿔가면서 최적의 우리의 선형함수를 만들게되는데,
Polynomial Features를 하면 여러가지 다양한 피처를 고려할 수 있게되어 더 많은 정보량을 받을 수 있기 때문에 모델 성능이 올라가는 경우가 있다.
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=2, include_bias=False)
poly_pipeline = make_pipeline(PolynomialFeatures(degree=2, include_bias=False),
StandardScaler(),
ElasticNet(alpha=0.1, l1_ratio=0.2)
)
poly_pred = poly_pipeline.fit(x_train, y_train).predict(x_test)
mse_eval('Poly ElasticNet', poly_pred, y_test)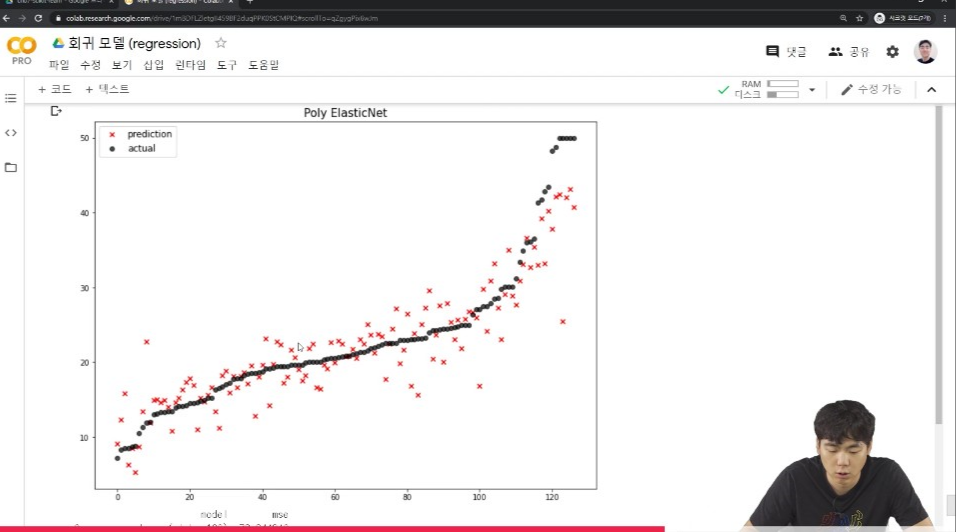
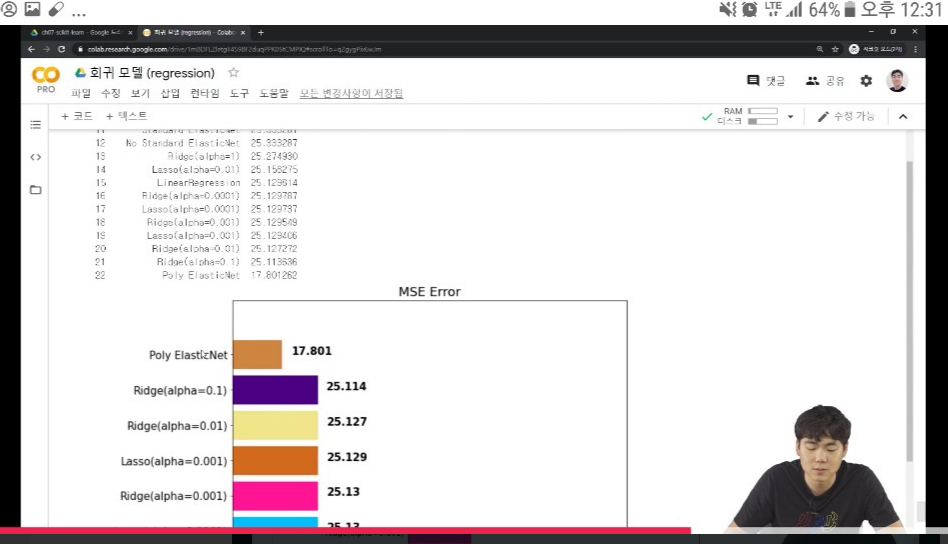
도출된 Regression 그래프를 보면, 실제값을 나타내는 검정점과 예측값을 나타내는 빨간점의 거리가 짧은 것을 보여주기도 하고 또 MSE Error 그래프에서 Ridge와 Lasso 모델에 규제를 한 것보다 MSE Error가 적기때문에 모델성능이 개선된 것을 알 수 있다.
📍앙상블ensemble
앙상블은 음악에서 합주를 하는 것 처럼 여러개의 머신러닝 모델을 이용해 최적의 답을 찾아내는 기법으로 보팅, 베깅, 부스팅, 스태킹 이렇게 네 개가 있다.
📍보팅 ensemble
보팅은 서로 다른 알고리즘을 넣고, 예측된 결과를 가지고 제일 투표를 많이 받은 것으로 결정하는 방식이다.
voting_regressor = VotingRegressor(single_models, n_jobs=-1)
voting_pred = voting_regressor.predict(x_test)
mse_eval('Voting Ensemble', voting_pred, y_test)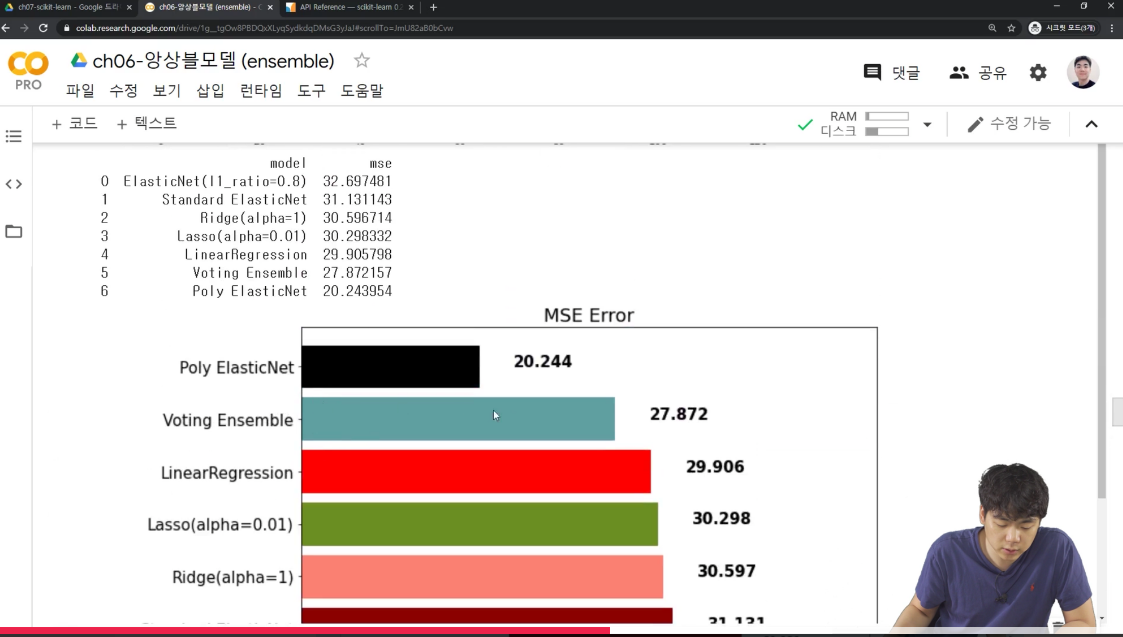
보팅 ensemble의 결과를 보면 저번시간에 보면 poly ElasticNet보다는 성능이 떨어지고linear regression 보다는 성능이 좋았음을 알 수 있다.
💡오늘 배운 내용 복습
-
Polynomial Features
-
앙상블의 개념
-
보팅 앙상블
04. Part1 40강부터 42번까지 수강완료!✊
직장인을 위한 파이썬 데이터분석 올인원 패키지 Online. | 패스트캠퍼스
왕초보도 진짜 데이터 분석을 하는 마법의 커리큘럼으로 파이썬 기초부터 다양한 예제를 활용한 분석까지 모두 배울 수 있는 온라인 과정입니다.
www.fastcampus.co.kr
반응형
'같이 공부해요 > 패스트캠퍼스ㅣ직장인을 위한 파이썬 데이터분석 올인원 패키지 Online' 카테고리의 다른 글
| [패스트캠퍼스 수강 후기] 데이터분석 강의 100% 환급 챌린지 47회차 미션 (0) | 2020.09.25 |
|---|---|
| [패스트캠퍼스 수강 후기] 데이터분석 강의 100% 환급 챌린지 46회차 미션 (0) | 2020.09.24 |
| [패스트캠퍼스 수강 후기] 데이터분석 강의 100% 환급 챌린지 44회차 미션 (0) | 2020.09.22 |
| [패스트캠퍼스 수강 후기] 데이터분석 강의 100% 환급 챌린지 43회차 미션 (0) | 2020.09.21 |
| [패스트캠퍼스 수강 후기] 데이터분석 강의 100% 환급 챌린지 42회차 미션 (0) | 2020.09.20 |





댓글 영역