고정 헤더 영역
상세 컨텐츠
본문
반응형
2020.09.11
[패스트캠퍼스 수강 후기] 데이터분석 강의 100% 환급 챌린지 33회차 미션
32회차에서는 머신러닝의 가장 기본적인 기본, 모델을 선언하고 → 학습해서 → 예측 순서를 배웠고 오늘도 이에 이어 머신러닝의 기본적인 개념 feature, label, test set, training set, 검증데이터를 배웠다.
📍 Feature 과 Label
머신러닝에서 feature과 label을 정의해줘야하는데,

x는 feature로, 학습에 넣어줄 데이터이고, 예측할 값은 빠져있다.
y는 label로 우리가 맞춰서 예측해야할 값을 말한다.
📍 Test set 과 Training set
Test set는 예측을 위한 데이터이다. 따라서 예측해야할 값을 포함한 '레이블' 값이 없이 feature만 존재한다.
👉x_test
이와 달리, Training set 학습을 위한 데이터로, 모델이 학습하기 위한 필요한 데이터 feature 과 label이 모두 존재한다.
👉x_train y_train
Test set set과 Training set는 '레이블'이 있냐 없냐로 구분된다.
📍검증데이터 validation
과대적합, 최적점, 과소적합으로 나눌 수 있는데,
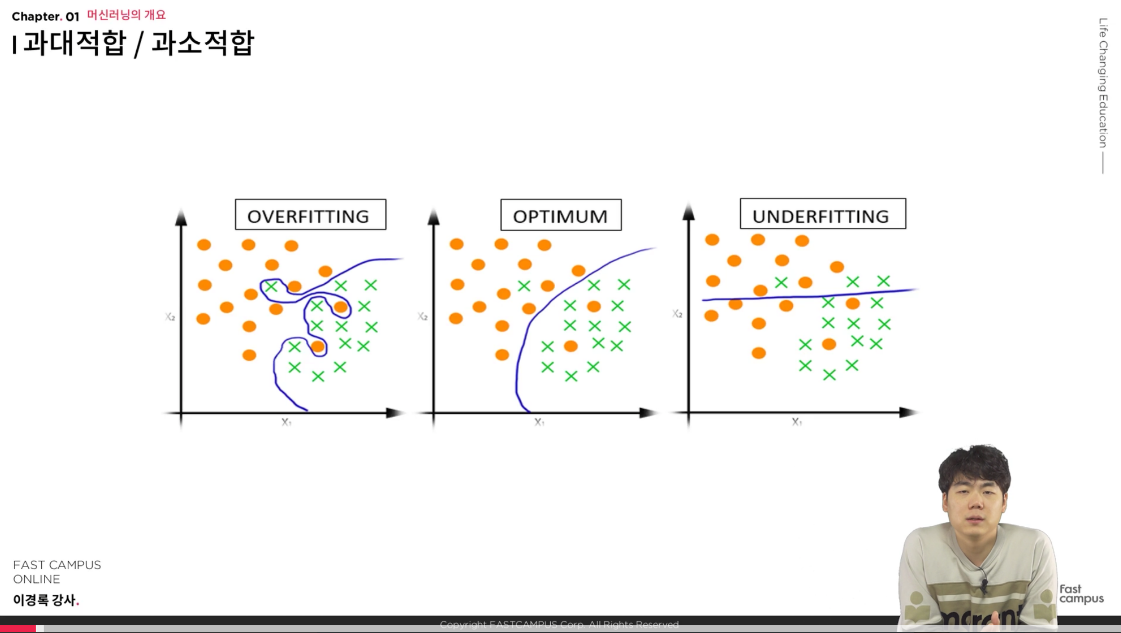
과대적합은 과대로, 지나치게 데이터 검증한 것으로 이해했다. 이 과대적합은 내가 가지고 있는 학습데이터에 대해서 분류 확률이 높을 수는 있으나, 실제 사례 적용시 성능이 떨어질 수 있다.
반면 과소적합은 학습데이터의 분류를 제대로 못하고 있는 것으로 이해했다.
❓그럼, 가장 optimum한 최적점은 어디인가?
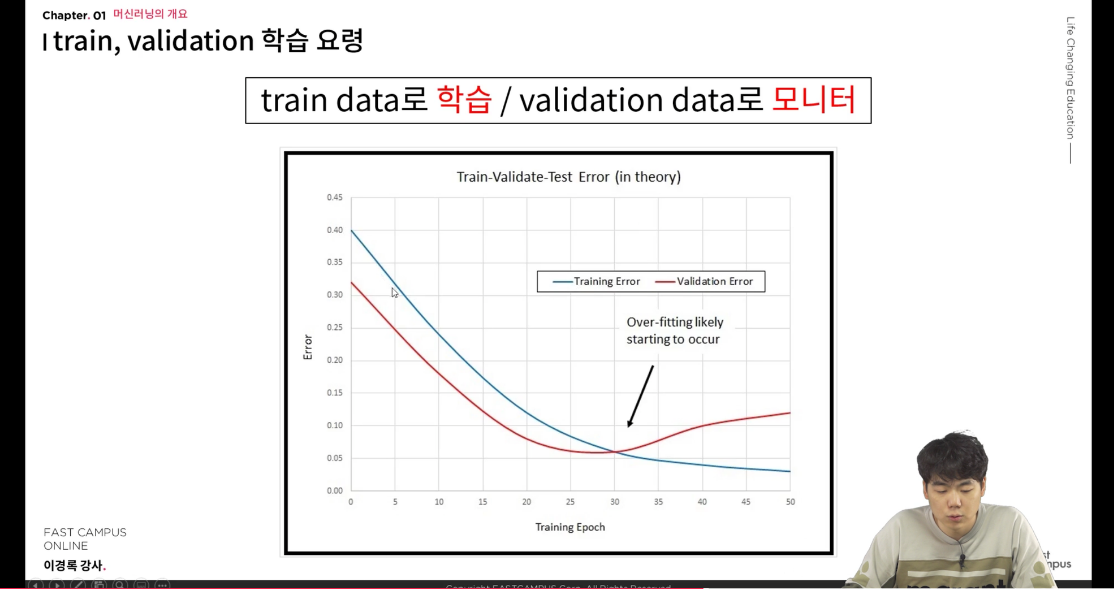
training set에서 학습을 위한 데이터와 검증을 위한 데이터를 8:2로 나눠준다. 학습을 시킨 다음에 validation error을 확인 했을 때, 위 그래프처럼 validation error가 감소에서 증가에서 바뀌는 변곡점이 제일 optimum 한 점이다.
💡오늘 배운 내용 복습
- Feature과 Label의 개념
- Test set과 Training set의 개념
- 과대적합, 과소적합
04. Part1 05강 & 06강 수강완료!✊
직장인을 위한 파이썬 데이터분석 올인원 패키지 Online. | 패스트캠퍼스
왕초보도 진짜 데이터 분석을 하는 마법의 커리큘럼으로 파이썬 기초부터 다양한 예제를 활용한 분석까지 모두 배울 수 있는 온라인 과정입니다.
www.fastcampus.co.kr
반응형
'같이 공부해요 > 패스트캠퍼스ㅣ직장인을 위한 파이썬 데이터분석 올인원 패키지 Online' 카테고리의 다른 글
| [패스트캠퍼스 수강 후기] 데이터분석 강의 100% 환급 챌린지 35회차 미션 (0) | 2020.09.13 |
|---|---|
| [패스트캠퍼스 수강 후기] 데이터분석 강의 100% 환급 챌린지 34회차 미션 (0) | 2020.09.12 |
| [패스트캠퍼스 수강 후기] 데이터분석 강의 100% 환급 챌린지 32회차 미션 (0) | 2020.09.10 |
| [패스트캠퍼스 수강 후기] 데이터분석 강의 100% 환급 챌린지 31회차 미션 (0) | 2020.09.09 |
| [패스트캠퍼스 수강 후기] 데이터분석 강의 100% 환급 챌린지 30회차 미션 (0) | 2020.09.08 |





댓글 영역