고정 헤더 영역
상세 컨텐츠
본문
반응형
2020.09.12
[패스트캠퍼스 수강 후기] 데이터분석 강의 100% 환급 챌린지 34회차 미션
32회차, 33회차에서 머신러닝에서 기본적으로 깔고가는 개념을 배우고 오늘도 마지막으로 '전처리' 에 관해서 배우고, 실습에 들어갔다. 개념을 하나하나 공부할때 이해는 되지만, 실습을 해보지 않아서 잘 와닿지 않았다. 이래서 실습이 필요한 것 같다.
📍 전처리Pre-processing
전처리는 데이터 분석에 앞서 데이터를 적합하게 가공,변형,처리,클리닝을 하는 방법으로, 사이퀼런 패키지를 활용해서 한다.
데이터 생김새가 다를때 데이터가 잘못되서 데이터를 수정하거나 제거해서 분석에 들어가야하는데 그대로 넣었을때 문제가 발생하는 경우가 있어 머신러닝 모델에 들어가기 전에 '전처리'가 중요하다.
강사님께서 데이터 분석가들의 80%시간을 데이터 수집과 전처리에 사용한다고 하셨다.

전처리를 하나씩 살펴보면,
- 결측치: 데이터빠진 부분 어떻게 채워줄지?
- 이상치: 이상치가 있을때?
- 샘플링: 샘플링을 맞춰주는 것, 예를 들면 하나의 클래스에서 다른 클래스에 비해 지나치게 많이 샘플링이 되었을때 맞춰주는 것.
- 피처공학: 피처들끼리 연산, 새로운 구간을 묶어서 정해주거나 scale을 변환해주는 등등
전처리는 이전에 dataframe을 가지고 주택데이터 클리닝을 할때 했던게 기억나는데.. 이거랑 비슷한 건가?하는 생각이 들었다.
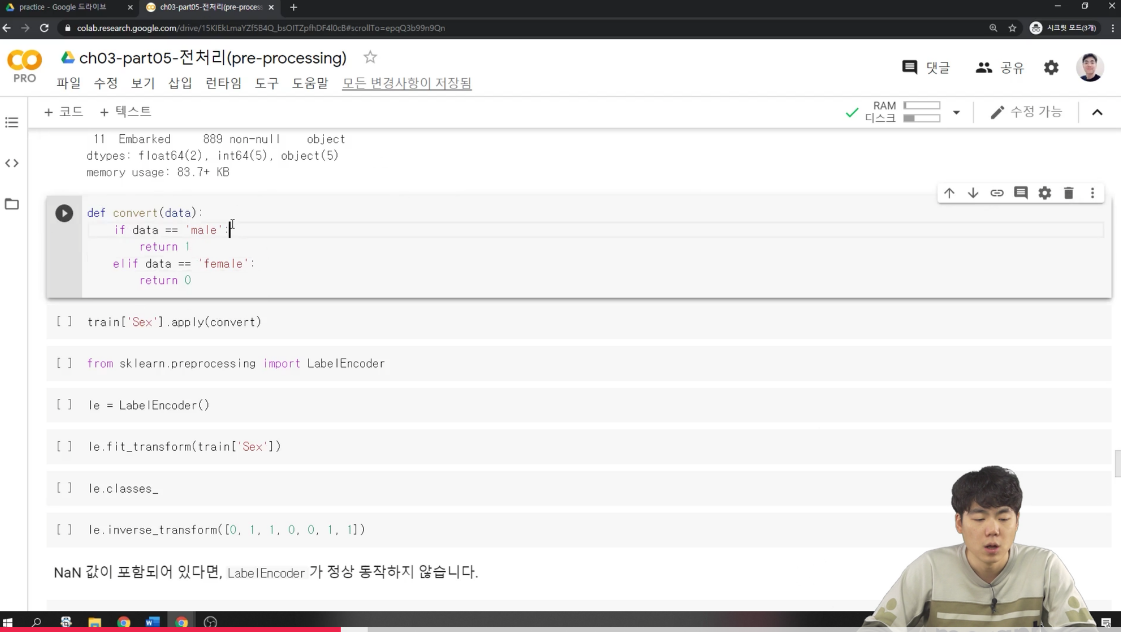
📎실습
seaborn에서 가지고 그래프를 그려봤던 타이타닉 데이터를 이용해서 데이터 전처리 실습을 간단하게 해봤다.
먼저, feature 와 label을 정의해야하는데
label(예측해야할 값): 우리가 맞춰야할 값이기 때문에 생존여부가 label이 된다.
feature = ['Pclass', 'Sex', 'Age', 'Fare']
label = ['Survived']
그 다음 return받는 데이터의 순서가 중요한데,
- test_size: validation set에 할당할 비율
- shuffle: 셔플 옵션 (기본 True)
- random_state: 랜덤 시드값→ 모델이 섞일때 랜덤 값을 고정시킨다!
from sklearn.model_selection import train_test_split
x_train, x_valid, y_train, y_valid = train_test_split(train[feature], train[label], test_size=0.2, shuffle=True, random_state=30)
x_train.shape, y_train.shape
x_valid.shape, y_valid.shape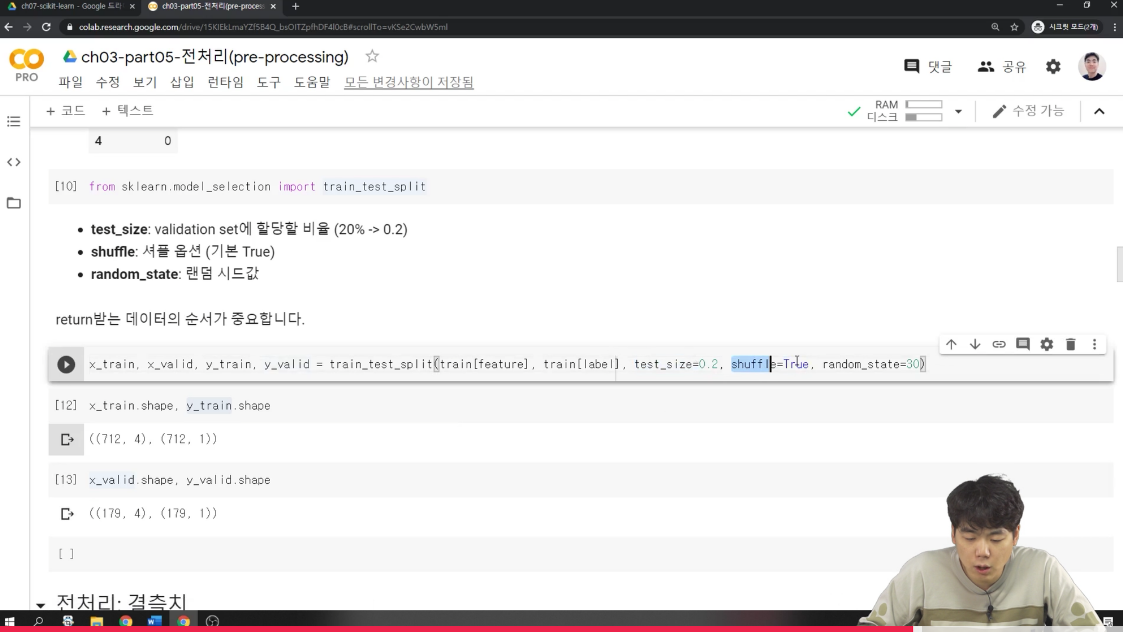
💡오늘 배운 내용 복습
-
전처리
-
전처리 실습
04. Part1 07강 & 08강수강완료!✊
직장인을 위한 파이썬 데이터분석 올인원 패키지 Online. | 패스트캠퍼스
왕초보도 진짜 데이터 분석을 하는 마법의 커리큘럼으로 파이썬 기초부터 다양한 예제를 활용한 분석까지 모두 배울 수 있는 온라인 과정입니다.
www.fastcampus.co.kr
반응형
'같이 공부해요 > 패스트캠퍼스ㅣ직장인을 위한 파이썬 데이터분석 올인원 패키지 Online' 카테고리의 다른 글
| [패스트캠퍼스 수강 후기] 데이터분석 강의 100% 환급 챌린지 36회차 미션 (0) | 2020.09.14 |
|---|---|
| [패스트캠퍼스 수강 후기] 데이터분석 강의 100% 환급 챌린지 35회차 미션 (0) | 2020.09.13 |
| [패스트캠퍼스 수강 후기] 데이터분석 강의 100% 환급 챌린지 33회차 미션 (0) | 2020.09.11 |
| [패스트캠퍼스 수강 후기] 데이터분석 강의 100% 환급 챌린지 32회차 미션 (0) | 2020.09.10 |
| [패스트캠퍼스 수강 후기] 데이터분석 강의 100% 환급 챌린지 31회차 미션 (0) | 2020.09.09 |





댓글 영역