고정 헤더 영역
상세 컨텐츠
본문
반응형
2020.09.28
[패스트캠퍼스 수강 후기] 데이터분석 강의 100% 환급 챌린지 50회차 미션
48회차랑 49회에서는 조회수가 높게 나오는 채널을 1위부터 100위까지 막대그래프를 그려봤고, 이번 시간에는 조회수가 높게 나오는 제목을 뽑아서 보고싶기 때문에,soynlp과 wordcloud를 이용해서 시각화해보는 실습을 했다.
👉 먼저 soynlp 설치 하고, LTokenizer로 단어의 경계를 따라 L-R 분리줬다.

여기서 L과 R을 알아야하는데, L은 한글에서 의미를 가지는 부분인 명사, 동사를 뜻하고, R은 을과 었어-와 같은 조사나 어미를 뜻한다. LTokenizer로 L인 의미를 지닌 단어만 추출해서 유효한 키워드를 알아 볼 수 있다.
df_hot_top = df_hot[df_sorted['views'] > 500000]
df_hot_top
👉주요단어만 남겨놓고 빈도수를 더해서 50만 이상인 영상을 추출해주고
df_hot['tokenized'] = df_hot['title_refined'].apply(lambda x: tokenizer.tokenize(x, remove_r=True))
df_hot
👉이렇게 일렬로 배열해줬다.
빈도수를 하나하나 따로 파악하고 싶기 때문에, counter를 이용해서 words의 빈도수를 파악하고 카운터를 딕셔너리형태로 변환해줘 각각의 빈도수가 표시되도록 출력해줬다.

from collections import Counter
count = Counter(words)
words_dict = dict(count)
print(words_dict)👉이 바탕으로, 워드 클라우드 그리기
from wordcloud import WordCloud
wordcloud =WordCloud(font_path='/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf', background_color='white', width=500, height=500).generate_from_frequencies(words_dict)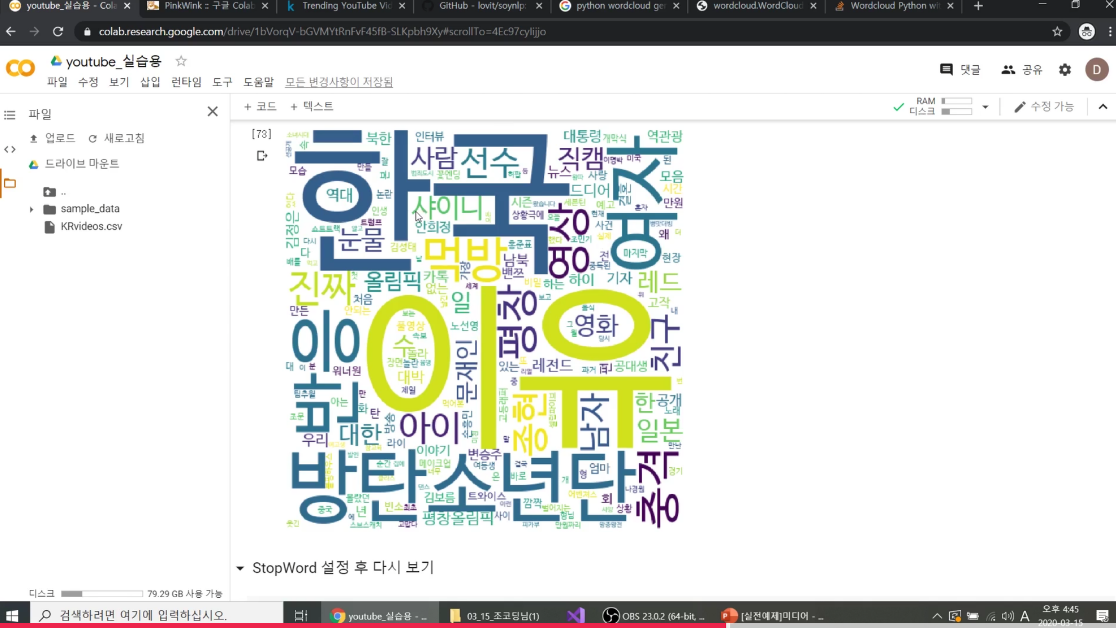
단어수의 빈도에 따라서 보여주는 것으로 어떤 단어가 인기가 있는지 알 수 있다.
인터넷에서 language?하면서 이런 그림을 많이 봤는데 이걸 내가 직접 출력하게 될 줄이야..
👉 Stopwords
WordCloud에 유효한 단어만 뜨는 게 아니라 수, 한, 온, 화 ,일과 같은 외자가 나와서 이걸 제거해주기 위해 stopwords를 코딩해서
stopwords = {'수','한','일','온','화'}
for word in stopwords:
words_dict.pop(word)하면 딱-
💡오늘 배운 내용 복습
-
LTokenizer을 이용해서 유요한 키워드 추출하기
-
WordCloud 출력하기
07. Part4 06강부터 08강까지 수강완료!✊
직장인을 위한 파이썬 데이터분석 올인원 패키지 Online. | 패스트캠퍼스
왕초보도 진짜 데이터 분석을 하는 마법의 커리큘럼으로 파이썬 기초부터 다양한 예제를 활용한 분석까지 모두 배울 수 있는 온라인 과정입니다.
www.fastcampus.co.kr
반응형
'같이 공부해요 > 패스트캠퍼스ㅣ직장인을 위한 파이썬 데이터분석 올인원 패키지 Online' 카테고리의 다른 글
| 패스트캠퍼스 데이터분석 강의 챌린지 참여 후기 (1) | 2020.10.13 |
|---|---|
| [패스트캠퍼스 수강 후기] 데이터분석 강의 100% 환급 챌린지 49회차 미션 (0) | 2020.09.27 |
| [패스트캠퍼스 수강 후기] 데이터분석 강의 100% 환급 챌린지 48회차 미션 (0) | 2020.09.26 |
| [패스트캠퍼스 수강 후기] 데이터분석 강의 100% 환급 챌린지 47회차 미션 (0) | 2020.09.25 |
| [패스트캠퍼스 수강 후기] 데이터분석 강의 100% 환급 챌린지 46회차 미션 (0) | 2020.09.24 |





댓글 영역